


Stop Experimenting.
Start Operating with AI.
Connect your systems. Centralize your logic. Automate mission-critical operations









Most enterprises run on operational knowledge that exists nowhere as a system asset. KAWA is a business process automation DSL that changes this — a single, human-readable file that encodes your workflows, approval logic, data pipelines, and governance rules, and deploys them as AI-governed workflows that both humans and agents can run, audit, and improve over time.
KAWA is an operating system for business and data processes. It provides the infrastructure layer between ad hoc data work — scripts on laptops, dashboards no one owns, workflows that run when someone remembers — and governed, production-grade operations.
KAWA handles scheduling, permissions, audit logging, data connectivity, and the user-facing interfaces that business teams use: dashboards, Excel-like grids, automated workflows, and AI agents. Analytical and operational processes run on KAWA without requiring a dedicated infrastructure team per project.
The central artifact is the workspace definition: a single YAML file that describes the complete state of a system — its data sources, scripts, sheets, dashboards, workflows, AI agents, and governance rules. The result is a business process automation DSL that treats the workspace definition not as documentation alongside the system, but as the system itself.
Business logic — routing rules, approval chains, escalation conditions, exception handling — lives in SOPs, spreadsheets, tribal memory, and ad hoc scripts. It may be partially documented and partially automated, but it is almost never versioned, portable, or executable. It cannot be handed off, audited, or operated by AI.
This is the architectural gap that limits enterprise transformation. The challenge is no longer digitizing workflows. It is expressing how the institution actually operates in a form that can be governed, scaled, and continuously improved.
The KAWA DSL addresses this directly: a structured, human-readable, machine-executable format for encoding the full operational logic of a business process — and deploying it as a governed, auditable system that both humans and AI can run.
Consider a global financial institution running a credit risk monitoring process. Every morning, Python models ingest overnight market data, compute counterparty exposure metrics, and flag accounts that have crossed risk thresholds. Results surface in a dashboard reviewed by the risk team. A workflow escalates flagged accounts to a human approval step before any action is taken. An AI agent answers analyst questions — "what drove the spike in exposure for this counterparty?" — drawing on the same governed data.
With the KAWA DSL, this entire system — models, data connections, dashboard, workflow, escalation logic, AI agent — lives in a single workspace definition file, stored in version control alongside the organization's other engineering assets.
That single file can be used to:
The gap between "we built something that works" and "we have a system we can operate, maintain, and hand off" collapses to a single file.
When a DSL file is applied to a KAWA instance, the platform compares desired state against current state and applies only the delta. New entities are created. Modified entities are updated. Removed entities are cleaned up. Deploying a system and documenting a system are the same act.
Every action is traceable. The workspace definition is a versioned document — every change is recorded, every deployment is reproducible. For regulated organizations, compliance is not a retrospective audit. It is a structural property of how the system is managed.
AI agents operating inside a KAWA workspace are grounded in the organization's actual data, governed by its actual permissions, and constrained by its actual workflows. The DSL is what makes AI reliable rather than speculative.
Because the DSL is precisely specified, AI agents can write it — closing the loop on truly AI-governed workflows from authoring through deployment. A technical lead describes what they need — ingest sales data from a CRM, compute team performance metrics, flag underperforming accounts, alert when model confidence exceeds a threshold — and an AI agent generates a complete, deployable workspace definition from that description.
This is not a roadmap item. KAWA ships with AI agents that author DSL files today.
The resulting workflow is naturally collaborative. A human sketches an initial structure through the UI; an AI formalizes it in the DSL. An AI generates a complete workspace; a domain expert adjusts thresholds, adds business context, and deploys. The DSL acts as the shared language between them — legible enough for a non-engineer, precise enough for a machine, authoritative enough for production.
The practical consequence: the time from identifying a business need to having a governed, production-ready system collapses from weeks to hours.
Teams can describe multiple versions of the same pipeline as parallel workspace configurations — different feature sets, model architectures, or training windows — all deployed to the same KAWA infrastructure, running on the same compute, writing outputs to the same governed sheets. Results across all variants are collected simultaneously and compared in a shared dashboard.
When a winning configuration is selected, promoting it to production is not a migration. It is the same workspace definition, reconnected to production data sources. The experiment becomes the production system.
A team building a customer churn predictor defines three competing approaches — Random Forest, XGBoost, and LightGBM — in the same workspace. Each is a Python script with an identical interface: same inputs, same output format, different algorithm. A single workflow loads training data once, runs all three models, and exports results to three governed sheets. A comparison dashboard shows accuracy at a glance.
When the team picks the winner, promoting it to production means removing the other two scripts from the YAML file. No migration. No rebuild. Just a smaller file.
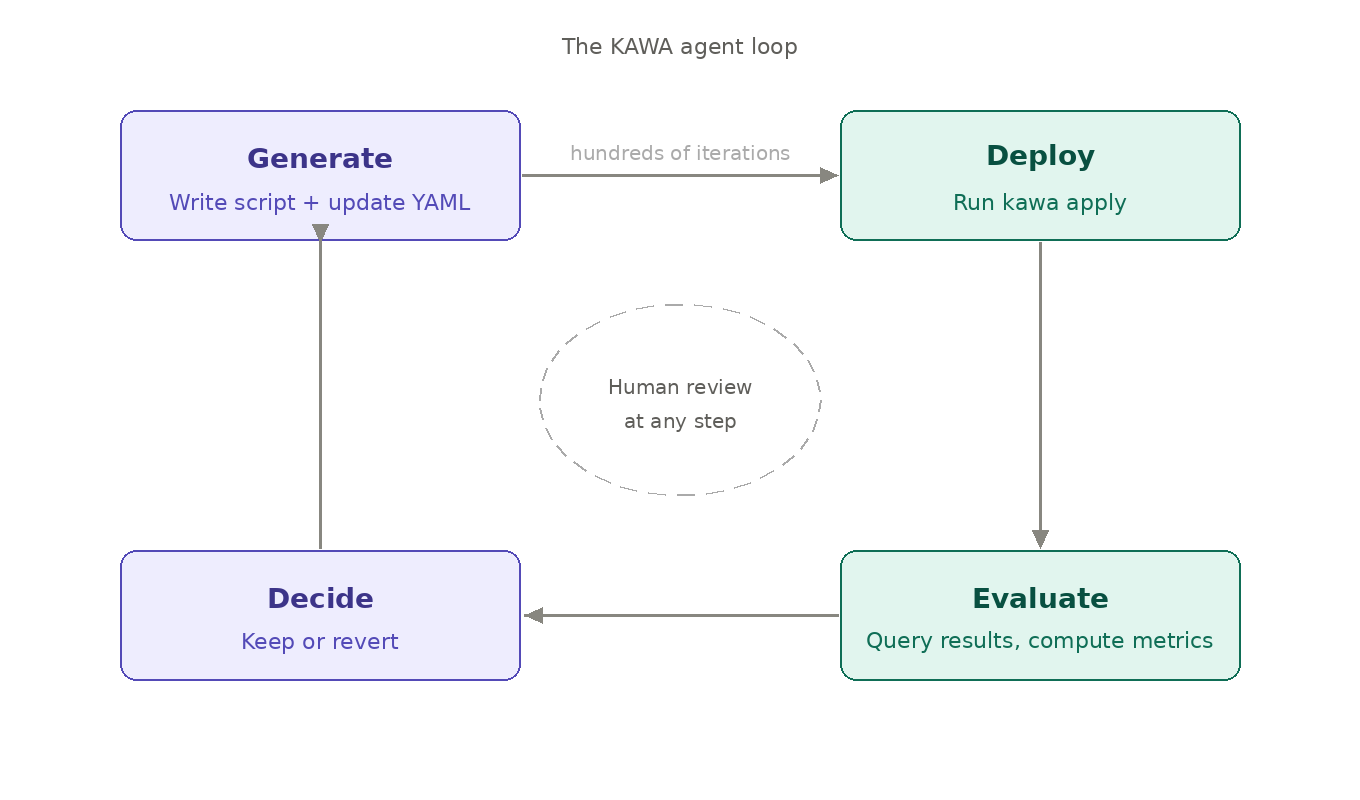
The bake-off above was orchestrated by a human. But the same cycle — generate a variant, deploy it, measure the result, keep or discard — can run entirely on its own.
An AI agent working within a KAWA workspace operates in a tight loop: it writes a new script, updates the workspace YAML, runs kawa apply, queries the output sheets for accuracy metrics, and decides whether the change is an improvement. Then it repeats. Hundreds of times. Without waiting for a human to review each step.
What makes this viable — and safe — is the structure the DSL provides. Every experiment runs on the same governed infrastructure. Every result lands in a queryable sheet. Every change is a versioned diff. At any point, a human can review exactly what the agent tried, what the metrics showed, and why it kept what it kept. The loop is autonomous, but it is not opaque.
The pattern extends well beyond machine learning. Any optimization problem expressible in the DSL — ETL pipeline configurations, workflow routing logic, dashboard layouts — can be handed to an agent to explore systematically. Wherever there is a measurable outcome and a parameter space, the loop runs.
The KAWA DSL is not locked inside a product. It is distributed as a standalone binary — kawa — that ships with context files, skill definitions, and documentation. Any AI agent that can read files and execute commands can operate a KAWA workspace.
When an agent is started in a KAWA workspace directory — whether it is Claude, GPT, Gemini, or an internally hosted model — it finds everything it needs: a workspace.yaml describing current state, skill files documenting exact syntax for every entity type, and the kawa CLI to apply changes. The agent requires no prior knowledge of KAWA. The context is self-contained.
This means AI agents become general-purpose operators of the platform. They can build use cases from a description, optimize data pipelines, automate data preparation, document existing setups, and monitor and repair workflows — all as versioned changes to a human-readable file. A human can review any agent action by reading the diff.
"What changed for us was having a single definition of what our system actually was. For the first time, we could deploy, audit, and hand off a process without it living in someone's head."
— Head of Quantitative Engineering, European Asset Manager
Every enterprise has operational knowledge. Almost none have made it durable.
The KAWA DSL changes this. By expressing the full state of a workspace as a single deployable document, it eliminates the configuration debt that accumulates in every manually managed platform. By supporting AI-assisted authoring, it compresses the time from business need to production system. By unifying experimentation and production in one environment, it makes iteration systematic rather than heroic.
The blueprint and the production system are the same thing. Write it once. Deploy it anywhere. Run it forever.

Connect your systems. Centralize your logic. Automate mission-critical operations
Connect your systems.
Centralize your logic.
Automate mission-critical operations
